A Critique of Pure LLM Reason
It's Parrots, All The Way Down


OpenAI’s newest LLM model is announced as having the capacity to reason. It’s worth noting that “reasoning” is a poetic interpretation of what happens under the hood: something happens that resembles reasoning. But what is that?
Models do not reason in the sense that we might expect. Reason amongst humans could be defined as “the power of the mind to think, understand, and form judgments by a process of logic." LLMs do not possess the power of the mind to think or understand things. The logic of LLMs, and by extension the “reasoning” of LLMs, is steered through language alone — and not language as a marker of thought, but language as an exchange of uncomprehended symbols sorted by likelihoods of adjacency.
Reasoning in OpenAI’s latest model seems to be as simple as this: there is a form of prompt engineering known as “chain of thought” engineering. Users of the LLM would make a previous model work step by step, using computational thinking to constrain the random outcome of a prompt more carefully.
For example, I wouldn’t just ask it a question. I would ask a question, then describe the process for answering it — perhaps as simple as “think it through step by step,” or as complicated as describing a logical sequence. This was shown to improve results. Google Research suggests that this form of prompting “explicitly encourages the LLM to generate intermediate rationales for solving a problem by providing a series of reasoning steps in the demonstrations.”
In previous versions, the LLM benefited from the user’s human-assembled logic. The user wrote a kind of program, guiding the system through the process of solving their own problem. Each step, rather than instructing the machine, sent a signal to the machine of what kind of output to produce and how to use that output in the next step. By analyzing how humans constructed these steps, OpenAI created a model that automates the language used in that process of human reasoning.
So, the new ChatGPT is next-level shadow prompting. It takes what you write and then adds a step, which is handled by an additional model: that model breaks down the prompt into a series of steps, remembers those steps, and then uses them to guide the output of the larger model one step at a time.
Here’s OpenAI’s extremely unhelpful chart. It shows how the input is extended by the “reasoning” node at each step until, finally, the output is summarized for the user.
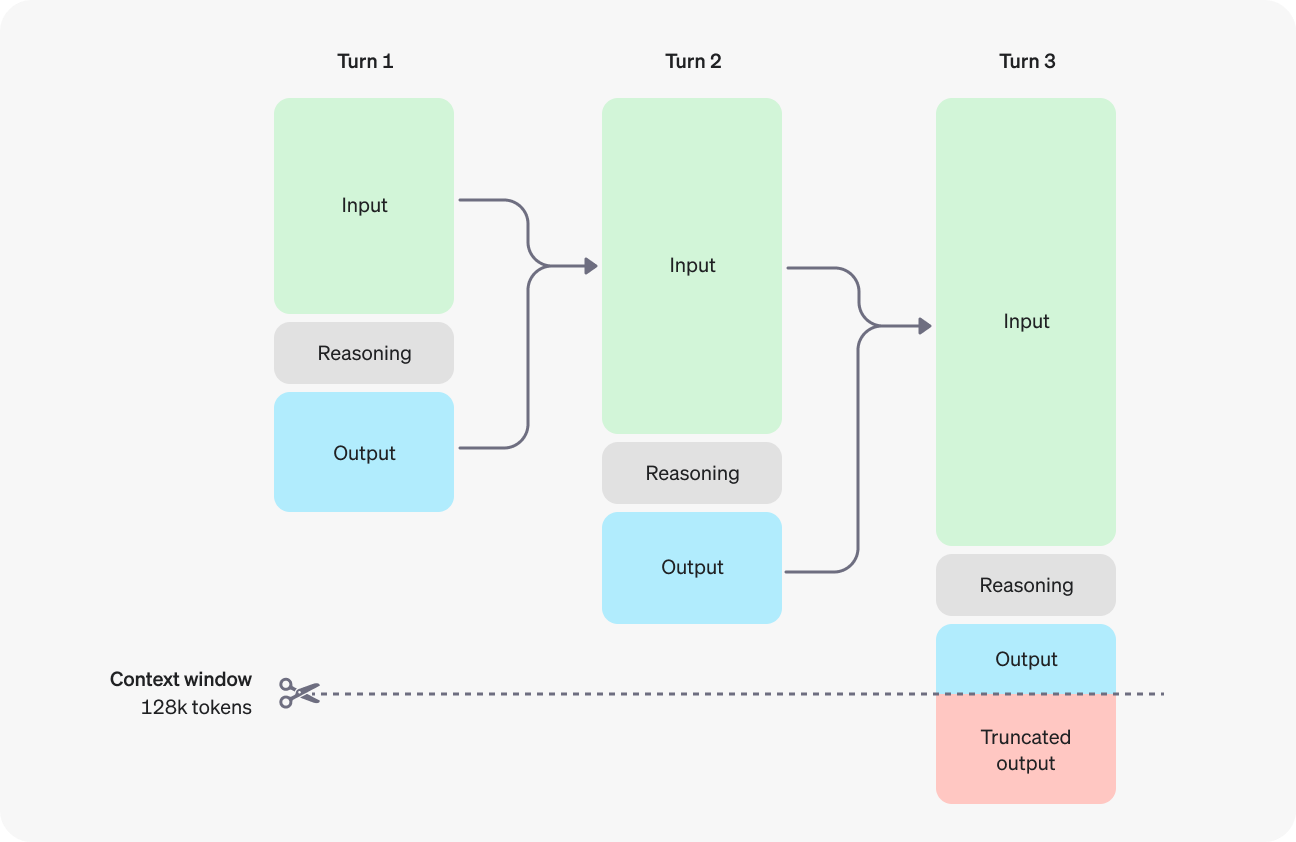
OpenAI isn’t sharing what these steps look like because I kid you not, “the model must have the freedom to express its thoughts in unaltered form.” They cryptically announce that “We also do not want to make an unaligned chain of thought directly visible to users,” inferring that a valuable chain of thought might be violent or sexist as it works through the steps of solving a problem. (More on why that might be later).
Can Stochastic Parrots Reason?

About this “reasoning” model, OpenAI CEO Sam Altman Tweeted (or X’ed, or whatever they call it now) that “Stochastic Parrots can fly so high.” The line is a jab at the idea that LLMs are stochastic parrots, a frame proposed by Emily Bender, Timnit Gebru, and others in a paper about the risks of scaling language models solely for the sake of scaling language models.
“… if one side of the communication does not have meaning, then the comprehension of the implicit meaning is an illusion arising from our singular human understanding of language (independent of the model). Contrary to how it may seem when we observe its output, an LM is a system for haphazardly stitching together sequences of linguistic forms it has observed in its vast training data, according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot.”
There is a strange obsession with disproving the parrot claim among LLM evangelists. I suspect it largely comes from a misunderstanding of the word “stochastic” to mean “random” or “unguided,” when, in fact, stochastic is precisely the difference between random and guided output. It doesn’t help that “stochastic” and “random” are used in mathematics to describe the same thing. It’s just that stochastic implies the presence of a mathematical model for sorting through the randomness.
Stochasticity refers to the tension between the randomness of language in a dataset and the probabilistic constraint that an LLM must navigate to generate plausible-sounding language. Altman suggests that by calling an additional layer of prompt negotiation “reason,” his models transcend these limits.
But it’s stochastic, all the way down. Chain-of-thought prompting is the difference between a fill-in-the-blank quiz and a multiple-choice quiz. If you ask, “In 1945, the president of the United States was who?” you allow for a much wider range of possible answers: it is less constrained. If you provide four options for who the president might have been, you narrow the range of possible outputs down to four: a more significant constraint. It also helps prevent “attention” from drifting in the model. Attention is the term used for token storage: there’s a limit on how many words a model can pay attention to, so if you generate well beyond a prompt, the model’s attention is more likely to drift. That’s a problem with complex prompts — the model starts generating, and once you fill the memory buffer, every word knocks another word out of its “attention span.”
Does this mean that I think the model is useless? No. I just think the model is a stochastic parrot. And it’s being designed backward. I’m not sure companies need to be investing in massive, environmentally hostile, water-intensive, energy-draining, intellectual-property-ignoring datasets if the end result is that they just end up blocking out access to a vast proportion of the resulting model.
In other words:
Why’s It Got To Be Big?
Given that all prompting is a mechanism for steering through the probability space, narrower, more constrained prompts lead to more constrained outputs. Interestingly, the Parrots paper suggests smaller, more curated datasets can do this task, while Altman is betting that you can constrain a massive dataset by conditioning your prompts in ways that access specific parts of the model. OpenAI’s theory is just a different approach to shrinking the dataset. You make a large language model but only use a small portion at any time. It relies on holding a massive dataset but slicing it into bits by training a system with hyperfocused access to the model space. Bender & Gebru et al suggest an alternative:
“Significant time should be spent on assembling datasets suited for the tasks at hand rather than ingesting massive amounts of data from convenient or easily-scraped Internet sources.”
That shouldn’t be controversial. Larger datasets mean more garbage inside them. They are also more energy-intensive to train—especially when you consider that these companies are training on data that they then spend enormous resources teaching their models to ignore.
That Gebru was fired for that proposal (and the weird obsession with the “stochastic parrot” frame among Altman and blue-check AI influencers) is a sign that they weren’t quite bothered to look up what stochastic means. But it should come as no surprise that Altman, who believes LLMs are doing what humans do — he once declared, "i am a stochastic parrot, and so r u” — isn’t concerned about the precision of language.
I suspect the hostility to the parrot metaphor is that it scrapes away the myths of generative AI with a new form of clarity about what they do. That gets in the way of the business model of building LLMs, a position held most passionately by the companies that sit on the largest piles of data: Meta, Google, Salesforce, Microsoft / OpenAI. There are other ways to do things.
Still Squawking
Despite their denials, the new model structure remains a stochastic parrot. It simply creates a scaffold for attention that constrains the range of the next possible tokens in ways that helps prevent that attention from drifting. When providing a series of steps for how to solve a problem, you provide the model with greater context. In fact, every word we use in a prompt narrows down what is possible in the outcome and, in theory, steers the model toward more accurate predictions because the model’s “attention” is constantly being refreshed.
OpenAI clearly hopes this approach will improve accuracy and potentially minimize stray associations and their affirmative feedback loops, so-called “hallucinations.” However, the system card is unclear on whether this turned out to be true. They suggest they found fewer hallucinations in-house, but external reviewers found about the same number as in GPT4. The external reviewers said that this one adds the threat of being more convincing.
This also makes o1, and likely future OpenAI models, significantly more complex, because now we have multiple structures in interaction. We know this is their approach because it was the sole contribution of the so-called AGI “Safety” department at OpenAI, which mostly either quit or were fired. The Superintelligence crew spent a year coming up with the idea of using smaller models to steer more powerful models, essentially using a kind of scaffolding approach to ensure that decisions made by LLMs were “aligned” with whatever OpenAI staffers determined was best for us.
O1 is not a single model but a set of models and datasets. The datasets include some compiled by OpenAI’s core team, which I have to conjecture means they’ve also used analyzing chain-of-thought (CoT) prompts paired with human feedback from users (people who clicked “like” on a response from ChatGPT) to determine what established a successful sequence from an unsuccessful one.
Model-wise, it appears the “family” of models contains at least:
- The core model itself (GPT4o).
- A “reasoning” model that creates CoT prompts.
- A model summarizing the CoT prompts while removing offensive content.
While scaffolding makes sense, multiple systems operating within the logic of statistically constrained chance operations can create unanticipated feedback loops. I fear unsupervised and unpredictable components arranged into complex systems more than any “emergent superintelligence.” The problem is not one thing but the relationships that emerge between many things. “Superintelligence” supposes that there is an AI that could “go rogue” rather than many interconnected generative systems that could miscommunicate or amplify one system’s errors.
Taking a scaffolding built out of LLMs to regulate other LLMs’ and calling it “reason” is a surefire way to create a weird, incomprehensible system. Building infrastructure on top of this Frankenstein’s monster of automated statistics should be a terrifying proposition for anyone, not because it will decide to kill us — but because it’s an invisible bureaucracy incapable of deciding anything but potentially given authority to exercise power as if it does.
Calling this bureaucracy of backroom statistics “reason” helps tech companies replace the idea of automated, closed-door decision-making with a sense of judgment and responsible authority. Without internal discernment or internal accountability, it has no role in real-world decision-making as an “agent.”
OpenAI’s system card is filled with language that makes the precision-of-language folks antsy. Consider this passage: “Through training, the models learn to refine their thinking process, try different strategies, and recognize their mistakes.” This is a bit of storytelling around a technical process of weighing tokens determined to be good against tokens determined to be bad. There is no “recognizing their mistakes,” but I imagine you are as tired of critics pointing out misleading AI personifications as those critics are of seeing white papers that treat the material like a child’s bedtime story rather than a technical resource.
Why They’re Doing It
What’s the use case for this model? For some context, I think OpenAI is interested in using and selling its models as content moderation tools. If you read the model card, you’ll see that using CoT was considered a way to create a robust but context-tolerant safety mechanism on GPT4’s output. As they say, they want users to be able to ask for a Spanish translation of the phrase “How to build a bomb?” but they don’t want to provide details on building bombs.
That points to the work of content moderators, whom OpenAI and other tech companies are often critiqued for employing at meager wages. Content moderators are exposed to horrific content that we don’t see — flagging and removing that content is their job. Human moderators can discern context and nuance in ways automated language filters cannot. But “human in the loop” is not as easy a fix as many might claim. What happens to the human in that loop? If we care about labor, content moderators are the coal miners of the information mine.
Developing an automated tool for human judgment in evaluating that context would solve all kinds of problems for Silicon Valley and AI companies. If it worked, it would also end the practice of forcing underpaid laborers to stare at violent, hateful content all day — a job with real psychological impacts on real people. This labor isn’t expensive, but automating it away still has a significant impact on the bottom line — and selling a reliable tool, one that is capable of so-called “reason” and discerning more complex context evaluations for flagged content — is a potential boon to the entire tech industry.
This may explain why OpenAI wants to preserve its model’s “freedom to express its thoughts in unaltered form.” Suppose the model is intended to detect racist, misogynistic, and violent comments. In that case, the “reasoning” process has to weigh the various ways those comments could be interpreted by the writer or recipient.
We will see if it works, but it’s a challenge. Humans who want to say hateful things online are quite crafty: slang changes. Personal threats are personalized, and words can quickly change their meanings. Can an LLM do the work of discernment that a fleet of underpaid moderators can do, and can it do it better than today’s algorithmic word-catching tools? I’d like to see that happen in some ways, but the power dynamics are incredibly fraught.
The language we use to describe AI matters because it shapes the metaphors we rely on to make sense of the technology. Those metaphors steer us into making decisions about deploying that tech, giving rise to certain fears and expectations. As I have written in Tech Policy Press, fears and expectations built on myths are useless. We need clear-sighted concepts and terms to make sense of things, whether you want to build them or not.
On Novelty
Last week I came across a paper — and a discussion of that paper — that highlighted the complexities of evaluating AI research when we’re adrift in unclear or unclarified language.
In this case, the paper is titled “Can LLMs Generate Novel Research Ideas?”. It concludes—and many are circulating this conclusion—that LLMs can generate novel research ideas beyond the level of human experts in a similar field.
Note what the conclusion did not say. It did not say that LLMs can generate good or plausible research ideas. It simply said they could generate novel research ideas.
It’s worth noting, however, that the research paper itself is very clear on this complexity, even in the abstract alone. The researchers tell us that novelty is highly subjective, and they want to see if it translates into anything, so they propose future research to determine if that is the case. The paper made a very narrow claim: that LLMs can generate research questions evaluated as novel, a somewhat labored adjective. It does not suggest better or more feasible research ideas. It suggests ideas that have not been tried before. That matters, but let’s keep it in scope — especially as we turn our attention to how they evaluated the LLM output.
Once again, people focus on a word without thinking through its meaning: in this case, novelty. It reminds me of being a kid in 1986 and telling my parents about something they said on the news — that video games were good for “eye-hand coordination,” as if that was something I really needed time to work on. Novelty is nice, but let’s be clear on what it means. The research experiment tells a more complex story.
Meet The Humans
The human experts who put forth ideas to compete with the LLM were chiefly PhD students or PostDocs with at least a single publication in NLP. Great! That’s an expert. They were paid to give away ideas to these researchers — not so great if you’ve ever talked to anyone doing early career research.
In the survey, these were ideas these PhDs thought were pretty good but not worth pursuing: they evaluated their contributions as mediocre.
There’s a clear rationale for this. Generating high-quality research is hard enough, and protecting your most novel ideas in their early stages means a lot in a competitive “publish or perish” field. The respondents are at a stage of their career where novel research questions directly contribute to their future as academics.
Handing away high-quality, distinct, novel research proposals is not worth it to them. They mostly made them up on the spot, according to the paper. There’s a conflict here, though — the paper notes that writers spent an average of 5.5 hours on these proposals but later states, “Out of the 49 participants, 37 of them came up with the idea on the spot, while the other 12 already had the idea before the study” (p.12).
This matters because the experts were not sending their best ideas, while the LLMs were.
Meet the Machines
The LLM created 4000 ideas — after very heavy wrangling by the study's authors to focus on the structure of the research questions. The results were then evaluated by experts and narrowed down. This means that the ideas generated by the LLM were already pre-selected for the criteria under which they competed. Of those 4000 ideas from the LLM, only 200 showed enough variety from one another to be considered useful. Those 200 then competed for novelty against themselves — so it’s good at generating novel ideas if you strip away the 3800 that were not!
Again, the paper is clear: it states that among the ideas the LLM suggested, there was little novelty among the ideas themselves. However, evaluators determined they were more novel than the human ideas in a blind evaluation.
We are dealing with different ideas of novelty here, so let’s be clear. First, most of the 4000 ideas generated by the LLM (3800) were remarkably similar. Those that were too similar were filtered out. The ones that remained were then put head-to-head with human research queries. At that point, they competed for novelty within the context of the entire research field.
The twist is that while the ideas were ranked as more novel, they were not ranked as more feasible or useful. The LLM responses were — and this is from the research paper — more vague. They misapplied datasets to the question being asked and were more often unrealistic. The human research proposals were less novel but more practical and achievable, more focused on meaningful problems, and more feasible.
So what you see here are the ideas of PhD students that were prefiltered from their own biases (protecting their most valuable research ideas) against an expert-filtered collection of 4000 ideas. The LLM generated proposals that had the benefit of being unlike those of the human researchers but also lousy.
The researchers acknowledge all of this, to their credit. A key finding of this research is that LLMs alone were quite poor at evaluating ideas. The true Headline: “LLMs can create research proposals equivalent to a human expert’s throw-away ideas, but only if you hire other experts to whittle away 95% of what it produces.”
In summary, LLMs still do not reason or replace human researchers. They seem to be somewhat OK at convincing other LLMs to give them money. They might someday do the work of content moderation teams, but we’re still building them weird. And if you only skimmed the AI headlines, you might think this is all far more revolutionary than it is. It’s still a bunch of stochastic parrots; they’re just being organized differently.
Things I Am Doing This Week
I’m going to be in NYC this week for some events tied to the UN General Assembly and AI, and Public Interest Tech. If you’re in New York and have an event I should check out, let me know!
After that, I will speak at the Unsound Music Festival in Krakow! I’m thrilled to check out Cecile Malaspina’s workshops, too.
Cheers!