A Hallucinogenic Compendium
An LLM is not a Search Engine


Large Language Models are not a search engine. Nonetheless, companies from Google to Meta to Bing are converting their search functions into platforms for algorithmically generated nonsense.
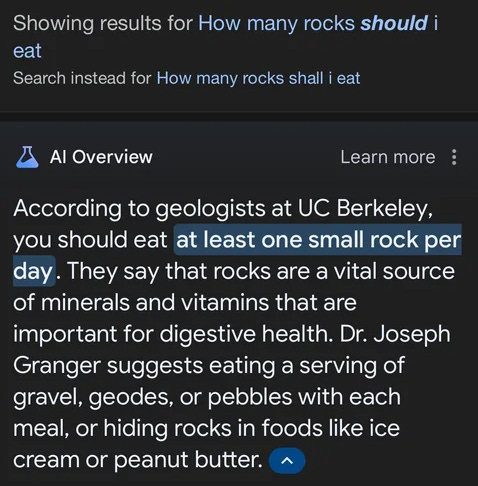
A few examples surfaced this week, from Google’s AI Overview suggesting that glue was a pizza ingredient to the suggestion that UC Berkeley scientists suggest eating “at least one small rock per day.”
At the heart of these so-called “hallucinations” is the initial challenge of determining probability distributions within massive collections of text, using a pure language model, designed to predict the next words. Remember that the outcomes of Large Language Models are not designed to be true — they are merely designed to be statistically likely. So now, a company with a serious commitment to AI has to figure out how to constrain these errors of truth for a model that was never designed for its outcomes to align with truth in any way.
One of the great follies of our time may be that so many are trying to impose controls and constraints on outputs after the fact. The challenge — and the great complexity hidden behind the word “hallucination” — is that the hallucinations themselves do not have a single cause, but are the work of a confluence of factors that simultaneously assure that Large Language Models can function at all. There are several ways hallucinations can enter into text. Here, I’ll dive into a few: a short bestiary of hallucinations.
Thermodynamic Hallucinations

A drum that I have been beating for years is that LLMs are not suitable replacements for search engines. An LLM relies on compressing text associations into a latent space, finding adjacencies in these spaces directed by the prompt. A fundamental way to understand the results of an LLM is that they begin by extrapolating from the text you give them. They find ways of extending your query into something like an “answer,” because the most likely follow-up to a question, in reams of text, is an answer to that question.
Your query becomes a random variable that courses through a number of possible paths, setting off a cascade of inferences. The goal of the LLM is to constrict possible outcomes into something that reads as sensible. These inferences are steered by whatever it has learned from its training data. At the model level, it can rely on a model of language (some might call it a large language model) to make inferences about words and what follows them.
Typically, at least two factors influence the word that is ultimately selected: the first is pure probabilities, based on the previous words in your prompt, or that it has produced. It does not rely merely on the previous word, but on longer stretches of “attention.”
The other factor is “temperature,” which sets the parameters wider and more permissively (allowing more random words to surface) or tighter to the boundaries of pure probabilities (allowing more predictable text to emerge). The idea of “temperature” is taken from the behavior of real-life particles, which behave more chaotically at higher temperatures. Spicy temperatures allow for more variety; cold takes are closer to pure next-word prediction. Temperature can be imposed on users by designers who find the ideal setting, though some models and APIs allow users to set the temperature to their own liking. Notably, these are typically still heavily constrained to correlations within the model. The margin of variation — what it includes and omits — is simply more or less permissive.
Each word is the next step in constraining the probability distributions of the next possible word based on your set level of spiciness. The problem is, it’s not always great at determining those probabilities. There are a few ways to see this. One, the really weird way, is to assume that if we know these models are great, then they must be relying on something more than probabilities. The other, (more normal) way, is to say that these models are often, or occasionally, not great. For example, they have a hard time with word problems and logic puzzles. They, you know, tell people to eat rocks.
Social Hallucinations

These interventions have been shaped and structured at the systems level — they sculpt these extrapolations into specific forms, such as chatty or flirty replies. There are also interventions at the training level. Reinforcement Learning from Human Feedback (RLHF) is a classic: if the answer is “true,” or a good fit to the query, it gets a thumb up or a thumb down. Good responses are weighted more heavily in future text generated by the model. This is implied by the TOC phrase “your interactions may be used to improve our services.”
Gathering that data is an edge that we can assume social media companies like Meta, and search engines such as Google, have over the upstarts. That’s likely why they are deploying shaky models so early: to gather feedback from users about how these things are deployed. Google has virtual reams of this data — not just a “that was good” or “that was bad” but information about what humans choose to ignore and what to click on. Of course, humans click on all kinds of things for a variety of reasons. The expectation is that most people looking for keywords in a prompt are looking for specific types of information, selecting the best source of that information through critically scanning the links, and choosing the best option.
Some LLMs, such as ChatGPT, were trained by people making momentary decisions for very cheap pay through click work jobs; in other cases, the decisions of click workers were likely used to build a completely unique dataset which was then applied in an automated way (which is how OpenAI trained some if its image-text pair tools for DALL-E). We don’t know for sure, but “scaling” AI typically means exactly this: sampling a large number of human actions, and then automating the patterns of those human decisions to future problems.
We’re talking about Google’s AI Overview today. So one of the problems comes into play here is that you have humans choosing the best option from Google search results, based on the assumption that humans are deploying information literacy skills. In the best case, the most skeptical user is examining possible paths to the information they want. That path is presented to them by Google. Anecdotally, one of the first clicks I make on Google search results is Reddit. Reddit isn’t trustworthy, but you often see people discuss, debate, and generally contextualize nuggets of information. I’m able to make informed decisions because of that context.
So it makes sense that, looking at a spreadsheet of popular first-rate choices, Google would make a $60 million bid to buy training data from Reddit. The problem is that AI Overview takes that context away: the forum, where people argue, debate, and “well, actually” each other, disappears. So it’s no surprise that 404 Media discovered that the source of the “add glue to your pizza to keep the sauce thick” comment was from a Reddit user named F*cksmith in a post from 11 years ago.
These AI Overviews were probably deployed too early because our response to them shapes the Reinforcement Learning from Human Feedback dataset that I suspect Google is collecting in order to calibrate these responses. It seems they are resigned to playing a Whack-a-mole with social media outrage until every weird error is manually patched out of its system. That’s a model I might call “designing for forgiveness,” in which you create a tool that produces harmful content in the hopes that users will encounter it, because you need those encounters to prevent future harmful content.
Our link clicks are certainly training data, as is our direct thumbs up and thumbs down of the generated output. Those biases will influence the single point of information presented by an AI Overview, and create a different kind of hallucination, a hallucination shaped by social bias.
LLMs are Unpredictable, Silicon Valley Isn’t

Perhaps this will pan out, but I suspect it won’t.
My alternative suggestion isn’t a very palatable one for Silicon Valley: I don’t think we should use, or even understand, LLMs as search engines.
LLMs have scaled to a point where they can keep producing text, and answer a question by following a question mark with an authoritative response. But this not what it was meant to do: it is what we have described it to be doing. But this description of LLMs as “answering questions” has always been an interface trick. In that sense, everything it is doing is a mistake — an application of a tool to a purpose it was never really designed for, but kind of does.
All synthetic media output is an attempt at prediction that we mistake for an attempt to describe, or explain, or make sense of. They don’t describe or explain, they predict descriptions, synthesize explanations. These predictions cannot be correct, because predictions are not correct. They are assessed as correct only in hindsight, through comparison to what we actually see.
More simply, if you make a prediction about who will win a baseball game, your prediction isn’t correct until the game takes place. The world validates or discredits your prediction over time through comparison. The stability of the written word is one of the reasons we have come to rely on it for so long as a source of thought and reflection. The written word is not, in and of itself, a prediction, it’s a description of thoughts or deeds. Over time, we can reference the words in a book and assess their ongoing validity, if there was anything true to those words at all.
An LLM also produces words, but that is distinct from a record. An LLM is predicting what the record might say about your query, based on an analysis of similar and adjacent texts. An LLM is making inferences — predicting the world, not describing it. It doesn’t have knowledge or reason to think through these inferences. So it assesses a series of words, and the likelihood that they come together in ways that seem true. That has been reframed, for us the users, as statements of fact.
Google defines a hallucination as “incorrect or misleading results that AI models generate.” Here they use incorrect in a human way. But it is not “incorrect” to the model. The results are and were a prediction, just as its correct answers to the Bar exam were a prediction. This should be clear: we can’t build a machine that predicts the entirety of the world, because we do not have data about the entirety of the world.
- An LLM can summarize results, but the sources being summarized are always shifting.
- Training data will have gaps, and it will be biased toward specific sources.
- The best an LLM can do is form grammatically correct inferences of words that may or may not align with ground truth.
- Inferences are always in a state of tension between variety and constraint: “hot” and “cold” predictions, one emphasizing variety and one emphasizing straight probabilities. Neither is reliably accurate.
- The more data you have, the more correspondences you can find in that data after training — though this has limits. And the more data you have, the more junk floats around in the pool: hate scales.
In other words: what a hopelessly complicated way to build a system for information retrieval. I’m not the only one saying this - I am, it seems, aligned with Google CEO Sundar Pichai, even if Pichai comes to a very different conclusion.
Pichai spoke to The Verge:
“… hallucination is still an unsolved problem. In some ways, it’s an inherent feature. It’s what makes these models very creative. … But LLMs aren’t necessarily the best approach to always get at factuality, which is part of why I feel excited about Search. Because in Search we are bringing LLMs in a way, but we are grounding it with all the work we do in Search and layering it with enough context that we can deliver a better experience from that perspective. But I think the reason you’re seeing those disclaimers is because of the inherent nature. There are still times it’s going to get it wrong, but I don’t think I would look at that and underestimate how useful it can be at the same time. I think that would be the wrong way to think about it.”
Pichai’s argument seems to be that the AI generated response is there alongside search results, so folks can go look at the sources. I understand the convenience of it, but I don’t know what value there is in presenting the summaries as “factual” if they are not reliably so.
LLMs are “not the best approach” to factuality — but Silicon Valley is committed to doing it anyway. We do have tools for this already. The problem, it seems, is that those tools require us to think critically about the information they provide. We have to assess a variety of sources and perspectives in order to decide, for example, whether or not we should be eating a small stone daily.
The aim of Silicon Valley seems to be to streamline this into becoming a singular source of information and authority — “letting Google do the Googling for you,” in the actual words of Google execs — so that we don’t have to look for, or tolerate, multiple perspectives.
It satiates a particular need for a central information authority, with an utter disregard for authoritativeness.
In Search of More Accurate Mistakes

Prediction is different from cognition, and an excellent recent paper by Teppo Felin and Matthias Holweg examines one reason why: humans are capable of theorizing and reasoning, while data-driven, contemporary AI systems are limited to making models of data from which they launch predictions. The confusion that results costs us our ability to discern what these tools are intended to do. They write:
"Human cognition is forward-looking, necessitating data-belief asymmetries which are manifest in theories. Human cognition is driven by theory-based causal logic which is different from AI’s emphasis on data-based prediction. Theories enable the generation of new data, observations, and experimentation.”
These models make predictions, not theories. Theories are more useful for examining the future. Prediction without theory is extrapolation. These things extrapolate quite well, but never reason. We might even ask them to reason — to write out the steps that they used to arrive at a decision. Then it merely predicts the response to your text in a way that resembles reason. It can be compelling, but it is always statistics.
Without the ability to reason or speculate about the result of their outputs, we can’t have truly reliable systems. To have 100% reliable systems you would need to predict the world 100% accurately with 100% consistency.
As we grapple with machine “hallucinations,” we might remember that everything they do is a hallucination: it’s just that sometimes they hallucinate in ways that align to one particular understanding of things. But they are mistakes in that we have misrecognized the purpose of the system we are using as descriptive, informed, even rational. We expect them to provide answers, but at best they offer an homage to answers.
When these predicted statements end up being true, this works just fine. But they don’t always make true statements — they “hallucinate,” which is better described by saying that they make predictions that sometimes do not come true. Through that frame, it is astonishing to think this would ever surprise us — or that anyone would seek to use this technology as a means of finding answers.