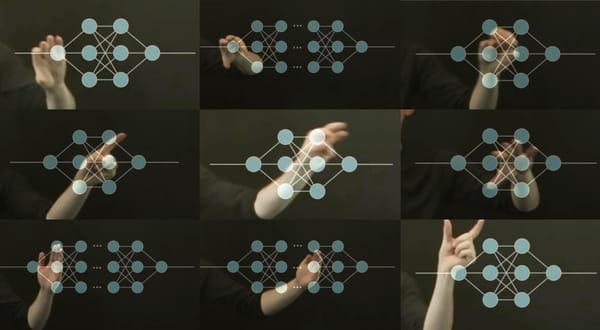
Ghosts of Diffusion
How the new generation of image-producing AIs tries to reverse entropy


AI generated images are a kind of spirit photography. Spiritualists of the 19th century hoped to scope an apparition through new technologies. Seeking ghosts in our film photographs reflects a relatable mysticism associated with new machines. Seizing opportunity, certain photographers would prep their film spools by taking pictures of a mock specter on a frame of film ahead of the portrait session. When the sitter arrived, their image would be superimposed on the pre-existing image of the staged ghost.
The folks who saw the images didn’t know that the image was already there. But in the image, they saw the dead, resurrected from disappearance, hovering over them in transparent relief. It was easy, then, to attribute cameras and chemistry with the power to reach otherwise obscured — literally non-living, unknowingly artificial — intelligences.
Old photographs still stir up a sense of connection to an "other" intelligence. Film allows us to connect to lost time, which today is an unappreciated miracle.
I’m reminded of this as I try to understand the underlying method DALLE2 uses to make images. I’m used to GANS, which lay beneath many prediction-based sound-and-image generating AI systems. Diffusion — the model that drives DALLE2 — is a little different.
From GANs to Diffusion

Years ago I worked with GANs to create something called the Costică Acsinte dataset. I created a dataset from the hundreds of public domain images taken by the 19th century Romanian portrait photographer, Costică Acsinte. Ascinte's work had deteriorated over time. They are torn, moldy, some are burned.
In 2019 I wanted to understand what it meant to put together a dataset for training a GAN. So I took the Acsinte archive and manually cropped the photos so that the subjects were at the center of the composition. I kept the damaged ones in the dataset, as a way of understanding how the GAN would interpret that noise.
GANS — generative adversarial networks — are neural nets. They discover patterns from images, map those patterns, and access those maps to generate (G) a “missing” image. That image goes into battle with another image it has already seen: the adversarial (A) part. If the image can hold up against a comparison to the real thing, it gets pushed forward. The best image from those battles emerges as your result.
To use the Acsinte dataset as an example, a GAN would make a map of pixel patterns in the dataset. It would then find common clusters and reproduce them. It would send an image over to its "adversary," which would compare it to real images from the training data. If it could tell which one was fake, it would reject it, and the neural net would try to make another. Eventually, an image would emerge that the neural net could not distinguish from the training data. That one would be shown to me, and I'd say "wow, AI is really something!"
Below is what AI image generation could do at the start of 2019. It’s one of millions of images that the Costică Acsinte dataset could produce, taken at random. You see that it learns the decay and noise, reproducing it, because to the GAN, the noise is inseparable from the subject. The ghost cannot be take out of the portrait.

Chasing Decay
Diffusion is a bit of an anti-GAN. Rather than fighting a picture battle in a neural net, a diffusion model takes an image and strips information out of it until it becomes pure noise. By degrading the image over time, and studying what happens as information is removed, the model is able to learn how images become noise. It remembers patterns from pure image to annihilated image. The model can then turn that noise back into an image. As it does this to millions of images, it becomes very good at turning noise into a wide range of images that might exist somewhere in the chaos.
There’s an algorithm that makes this pattern finding possible. I have no idea what it is or how it works, because it is a Greek alphabet soup of equations. But just know that it’s there. There’s a math problem that does this.

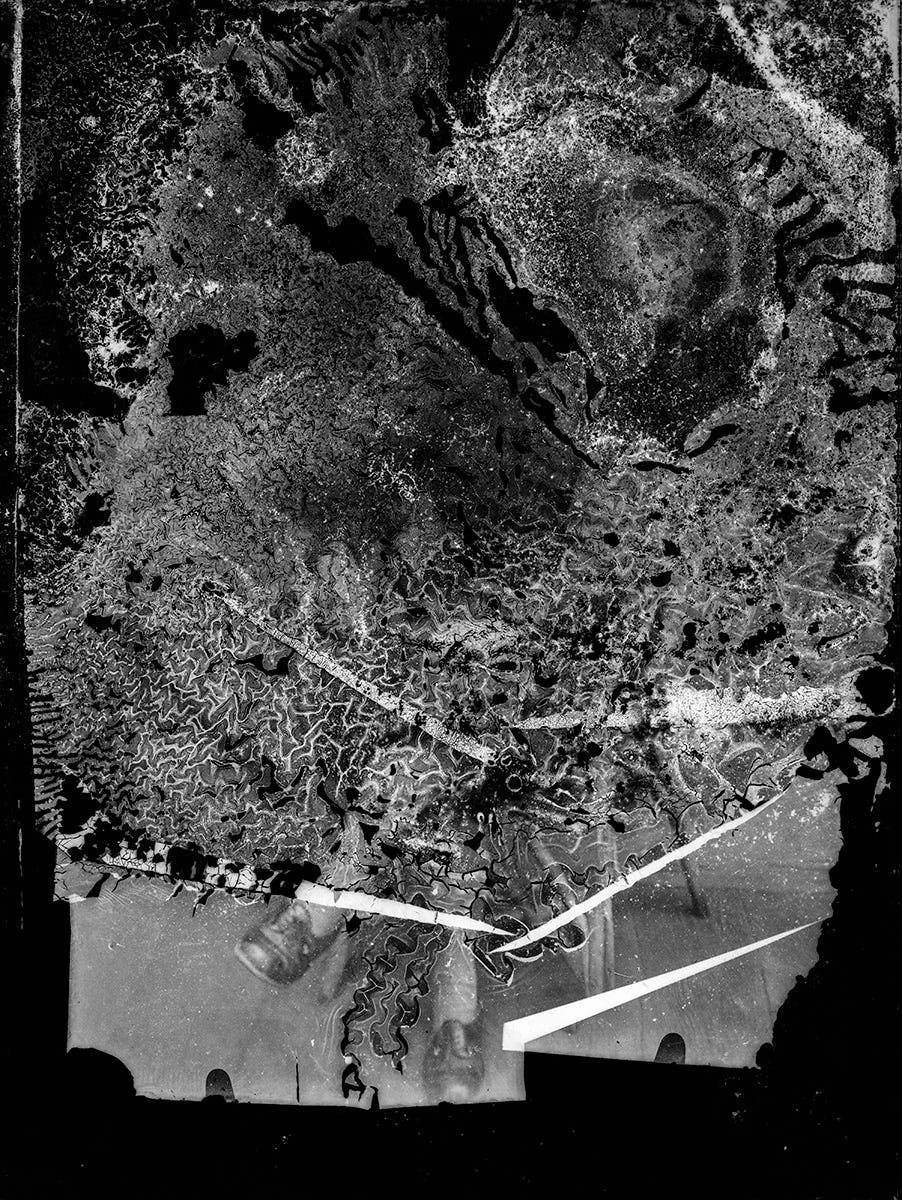
Another way to think about it is by looking at the Costică Acsinte archive. The images in that archive were on film, and they degraded over time. The mold and creases, the slow decay of photographic inks. Imagine sitting and watching the decay of these images over the course of a century. Think about the notes you might take if you had that kind of time, to trace the gradual spread of bacteria or creases on every picture.
The trajectory of that decay is going to follow certain rules. Imagine taking a photograph of a decaying photograph every day for a hundred years. Someday, when the photo is nothing but a pile of paper, you'd have documentary evidence of what it once was. And you could use that reversal to understand how to create a replica of the source image.
As you did that, you’d also be able to generate a basic set of rules for how decay spreads. And that means you could simulate the decay on all kinds of images. You might be able to generalize patterns in the ways creases creased and the mold molded. You could reverse time to see what a clump of mold looked like, on a film plate, a hundred years ago.
Or at least, that's what we think we could do. Like the spirits in the cameras of the era, we'd actually only be able to make believable imaginaries. But this tracing of decay is nonetheless amazing.


DALLE2 learned how images deteriorate when information is taken away from them. Then it learned how to recreate images from the noisy end state. As a diffusion model, any image it produces starts as a jpeg of random noise. DALLE2 peels the noise backward to "arrive" at an imaginary start point. Where GANs were all about prediction, Diffusion models like DALLE2 are about repair. Diffusion models (Disco Diffusion, Midjourney, and DALLE2) have already dissolved our archives of images into pixelated noise.
But the repair is not accurate. Like the ghosts in spirit photography, the repair of an image lost to noise or decay will always be an illusion. The image above is a “completion” of the photograph based on what DALLE2 sees. It isn’t applying its studious notes on digital decay to recreate something. It’s using it to guess. The mistakes we make in our dealings with AI are mistaking the machines guesses for facts, or truth, or purpose.
Your prompt tells it which noise paths to follow: rather than telling it to go left or right, you tell it to go “more koala” or “more koala with a top hat.” In the examples above, I told it to generate a black and white portrait of a man. The AI weaves its way through the noise looking for information that fits that description, based on text associated with the images it had previously dunked into a pixel acid bath.
Whenever people show you a conversation they’ve had with a text based model, or a photograph an AI created, keep this in mind: the same source image, taken above, could have been any number of things.


What I love about Diffusion is that it’s all about finding signal in the noise, but that signal is absolutely arbitrary, like a dream. The foundation of every image is not a blank image which DALLE2 adds to. Instead, it is like finding constellations within a dense cluster of tightly connected stars. The concentration of these clusters is dense enough that, rather than seeing three stars and calling it the belt of Orion, you can name the belt of Orion and DALLE2 will find it somewhere in the scattering of light.
DALLE2 was trained on our own work — it scraped the internet for our drawings, photographs and sketches, scratching away information until nothing but the glitch remained, and then reassembled them. It took notes on all the possibilities between our art and memories and oblivion.
If DALLE2 amazes us by creating these images, we are amazing for making them. The seduction of DALLE2 is in stripping that mass of memory and creativity down to nothing and then dazzling us with its reassembly. The paths of decay and deterioration that it traced are our own.
As always, we should avoid the trap of attributing these images to an “AI.” As I hope this explanation makes clear, the AI isn’t actually creating art or images. The AI is tracing trajectories of decay and anticipating different possibilities hidden in those patterns. That is remarkable enough. The AI is taking our prompts and matching them to previous examples of that decay.
Perhaps DALLE2 is a kind of spirit photography for images themselves: a visual media has become ever-present and starved of meaning. DALLE2 doesn’t make pictures that have “never existed,” it makes every picture that has ever existed. It’s made this possible by stripping away all possible communication potential of the image, rendering it into absolute noise, and then pulling it back from the brink of obliteration by assembling new variations from the carrion.

Thanks for reading. If you’d like to share this newsletter, please do! And if someone shared it with you, consider subscribing. It’s free, but donations are accepted.