Reverse Diffusion: Chance x Prediction
A presentation for the Taming of Chance program


Below is a text offered for my presentation at The Taming of Chance Program at Gallerie Stadt Sindelfingen in Germany on 20 April 2024. The description of the weekend series is below, with my presentation text below it.
Taming of Chance explores the possibilities of binary architecture. Kits with modified binary dice serve as a starting point for interactive and participatory experiences. The playfulness goes back to the game metaphor of dice, but also to the game of chance. We are faced with a paradox because, due to its architecture, a computer cannot emulate real randomness, since algorithms, tamed by reduction and order, cannot leave anything to chance. On the other hand, we are constantly guided and controlled by algorithms. The attempt to undermine this determinism playfully or artistically can be found, among other things, in the approaches of the Situationists (e.g. Guy Debord's wandering around Paris with a street map of London) or in Fluxus (e.g. a negation/abolition of chance in Robert Fillious Work One. Un. One.) who have taken the game of chance to the extreme. The dice boxes were distributed by Olsen to !Mediengruppe Bitnik, Evan Roth and Eryk Salvaggio to further develop the content. The rules created and the way in which the contents of the box are to be handled are presented by those involved.
Reverse Diffusion: Chance x Prediction
As a contribution to the Taming of Chance project, I wanted to reimagine the AI generated image as something that emerges from tensions between chance and prediction. How can we unpack the image by rethinking this relationship? What might we learn by inverting it? And most importantly, how would such a thing work? What would the rules be?
To do this, I looked back to a 1957 text by George Brecht, Chance Imagery, which was published by Dick Higgins’ Something Else Press in 1966.
In this essay, George Brecht describes his desire to find, or make, an image that is completely free of human bias, specifically the bias toward what images are supposed to look like. Brecht is the creator of the “event score,” a form of instruction for the creation of specific “events” associated with Fluxus and Happenings. Brecht came to these scores through a fascination with chance, crafting minimalist sentences that suggested the unfolding of a scene (the event). Slight variations would inevitably emerge as they moved from page to performance.

Here’s one example, Drip Music. Brecht has created an instruction for a musical piece. This musical piece shows a clear inspiration from pieces such as John Cage’s 4’33”. In Cage’s piece, the audience sat and watched him sit silently at a piano. The piece involved moving the listener’s attention from the piano player to the room around them. Brecht wrote many scores, and much of the Fluxus movement of the 1950s and 1960s were built around this new idea of music.
But let’s look at the piece itself. A condition is made, that is, there is a boundary that is set. We are asked to do this ourselves, and the tasks are described clearly. The card is meant to create the conditions for a performance that will direct our attention to the sound of water dripping. And on the one hand, this is a case to say: “there is music everywhere,” which is now a fairly banal truism. But Brecht’s attention to sound and chance runs much deeper. In that 1957 pamphlet, which was written before Brecht knew who John Cage was, he was preoccupied by the idea of chance: not in music, but in images.
In English and, as I understand, also in German, Chance comes from the Latin word, chancere, “to fall,” which was used to describe the falling of the dice. Brecht describes chance this way: “when the cause or system of causes responsible for a given effect is unknown or un-looked-for; or at least, that we are unable to completely specify it.”
He then connects this to art: images made with unknown origins, whether because they come from places beyond human comprehension, or because they come from mechanical processes not under our control.
Working today, in the era of images generated by machine learning models, I began to wonder if the images we make with Midjourney and Stable Diffusion could be opened up by thinking about this dynamic. These are tools designed to confuse the difference between mechanical processes and the human unconscious. When we prompt a model in Midjourney, designers force us to click on a button labeled “Imagine.” When we prompt Dream Studio, we are asking it to “Dream.”

But these images are not the result of dreams, they are the result of a mechanical process. This is a mechanical process called a diffusion model, which relies significantly on chance, but that chance is sculpted by math toward something predictable. It analyzes the pixel information across billions of images, and maps those clusters to words.
These machines are not arriving at new pictures through chance alone. There is a chance element: the randomness of this noisy jpeg at the start of the process. That noisy jpeg is then filtered. The filter is a result of training data, which contains traces of bias, because by nature they cluster similar objects together and favor the most common representations of those things.
As a result, the paths these machines make as they constrain noise into images are deeply biased by human sensitivities, human subjectivities, human preferences and human ways of making sense of the world. They are not human themselves, these machines have no personal subjectivity, they simply order pixels according to the way they are most likely to appear in an image.
Brecht was interested in true randomness, not AI: which at its core is a kind of predictive analytics. AI looks at the past and aims to predict the next thing in the sequence. For Brecht, statistical probabilities were a constraint, and Brecht wanted to move away from what was predictable: he wanted to move away from biased images. His idea of bias was the bias of the human eye: referentiality. The fine art world was and remains biased to the context of its time, the visual formulas and systems of other painters and artists. We make sense of images through their relationship to other images. This idea of human bias remains in the AI generated image, even when they are generated through unknowable processes by black box machines.

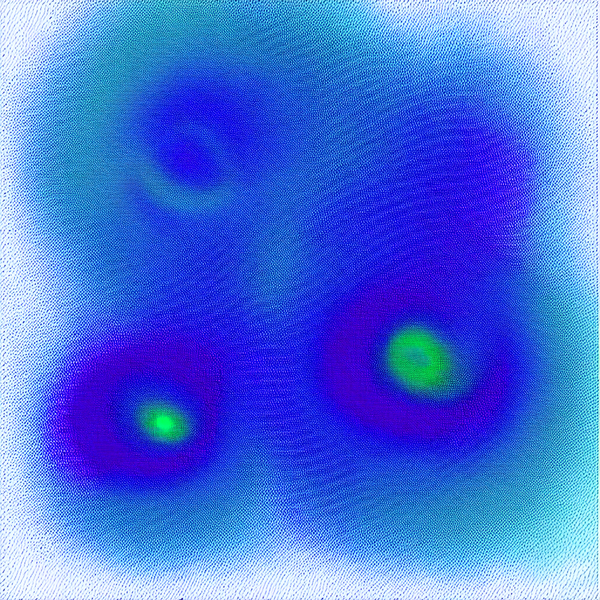
When we look at an AI generated image, on the one hand, we might see all kinds of variety, all kinds of unexpected decisions, as a result of this random starting point. Noise is essential to novelty and variety. Glitches, errors, mistakes and misinterpretations (as above) are where the novelty comes from.
But if we scale outward, and look at what is created from a distance, what we see remains in the known visual category of images: these images are still constrained, they are references to photography, illustration, human bodies and so on. These images depict similar things in similar ways. AI generated images, free of human intervention, rarely offer new perceptions for us. It simply references what else exists: fashion photography, video games, advertisements. If we create enough images, we will find patterns in the images we make: repetitions that point us to the central tendencies of the datasets they trained on. We can work within these boundaries, and many post-photography AI users create beautiful, thoughtful work. But we are unlikely to create a new visual experience or mode by relying on existing references. Contrary to belief, not everything is a remix: innovation and new ideas remain possible.
When I was invited to participate in this project, I was in the midst of some calculations. Calculations are not pleasant for me: I have a condition called dyscalculia, which means that any number in my head, when placed adjacent to another one, has strong odds of being reversed or shuffled. This makes me terrible as an accountant, but excellent for chance operations: I can make even a telephone number into a roll of the dice. So the math that follows may not be perfect: my sense, instead, is to give you an idea of scale.
Nonetheless, I was eager to explore a strange and perhaps pointless question. The question was this: How many decisions are involved in a computer image? I ask this because I work often with images generated by artificial intelligence, where the numbers of data points that shape an image are unfathomable.

A punchcard, in the 1940s, held 80 bytes of information; that’s about 640 yes / no decisions. This information would be stored on a piece of paper with holes punched into them. And I have been thinking that the images we share on social media, in the age of artificial intelligence, are much like these punchcards — only now the holes are smaller.
It’s not unusual to have 16 million pixels in an image; which is an absurd number of bits. Every one of those 16 million pixels may now serve as a set of instructions for a machine. It tells our AI images systems how to make a picture. The machine will break apart that image and convert it into noise, noise that follows a standard Gaussian distribution, and then it will memorize how it broke apart and walk it backward. That is how we train diffusion models.
When we want to create a new image, there is an element of randomness - of chance — introduced into the machine’s process. Rather than seeing a wall of static that the machine has seen before, it is given a random image of pure static. It scans this noise and finds patterns that resemble something in the prompt, and then it begins removing randomness from the image,to make it look more like something in the words we’ve used.
So it begins with chance, but then, unlike Brecht’s dream of an unbiased human art, the machine begins to write bias into randomness, steering it toward a picture of something we’ve asked it to show us.
So what you are about to see is a piece of software that generates pixels without any reference to human cultural bias, but instead attempts to create an image through pure chance. If Artificial Intelligence is a tool that predicts the next step in a sequence, we want an artificial unintelligence, a machine that makes no predictions at all. The result would be what Brecht might call a chance image, an image unburdened by references to other images, or to human biases of what images should contain.
As an artist I am interested in these processes, and in the creative resistance to AI. So I thought it might be fun to write an image in this way by hand. The Taming of Chance offered me one way to do it: take one die, which can make one decision: 0 or 1, yes or no, on or off. But then we can scale out: add more die, add more decisions.
Start with 8 die. That is not merely 8 decisions, but 256 decisions:
- 8 bits x 2 states per bit
- 2×2×2×2×2×2×2×2 = 256
We can create a simplified 8-bit computer system, where each of those numbers represents a decision about a color. The way we represented color in RGB terms was eight slots, each of those slots with a one or a zero. Each pixel has 8 bits, so that’s 256 possible shades of color. For our purposes, 0 and 1 are blue; 2, 3, and 4 are green, and 5, 6, and 7 are red. This, it turns out, is another human bias: we have discriminated against blue, because shades of blue were harder to see. It’s the bias of the human eye, but let’s move on.
Initially I intended to set out to roll the dice once per pixel in a 640 by 480 pixel image. When the dice totalled up to one of these numbers, its corresponding color would be added, by hand, to a digital jpeg. I thought that this kind of absurd process would yield all kinds of interesting results. 640 x 480 is not a large image. But one 640x480 image means more than 2 million decisions.
A MidJourney image, at its highest resolution, is more or less ~ 7,372,800 x 256 decisions, and that is only the number of pixels in the image: the actual number of “decisions” that inform the colors and combinations of these pixels is far higher, so high it would be difficult to measure.
Chance Operations (For George Brecht)
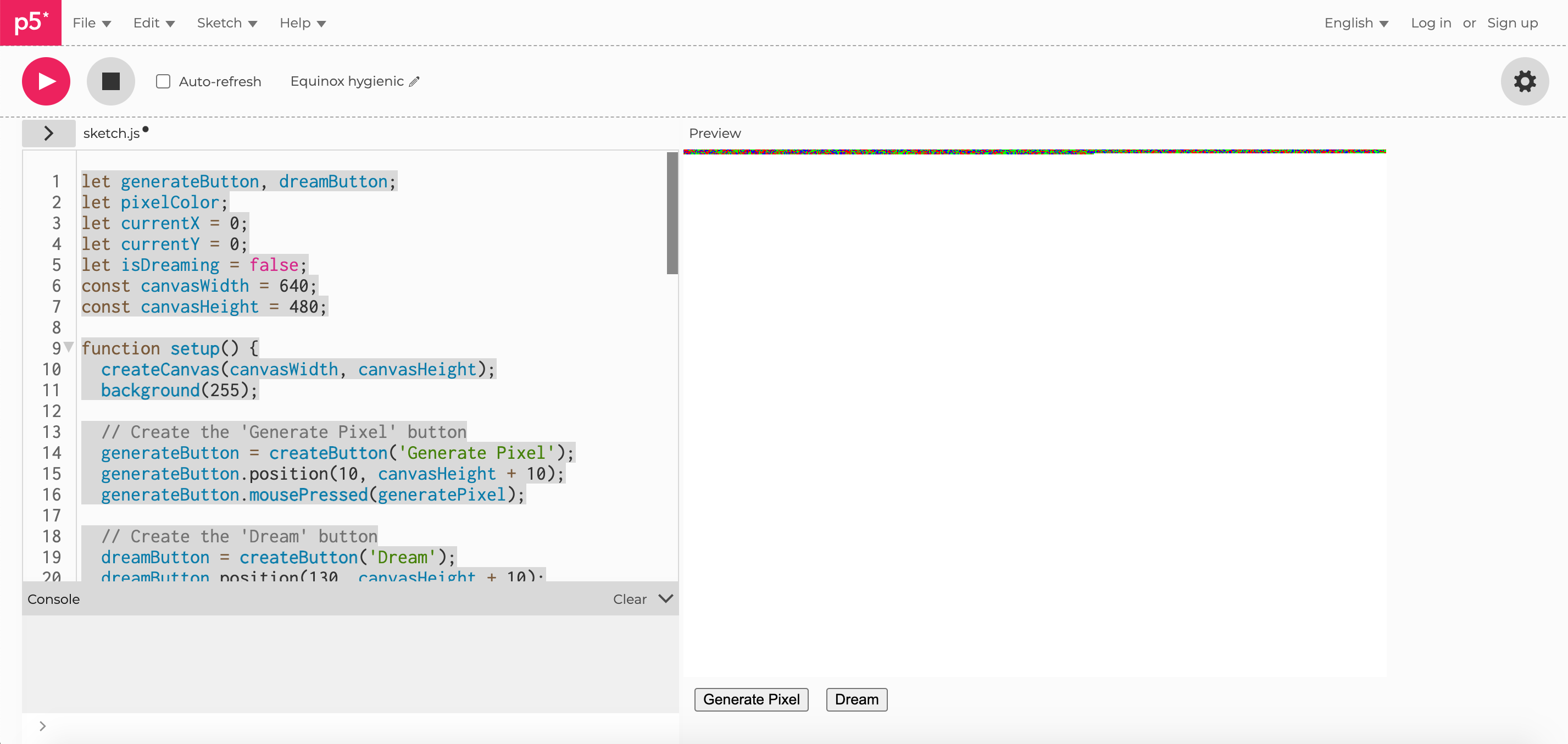
Software engineering, at least in theory, is about solving problems. So I wrote some code to solve my problem. Using Olsen’s dice — which have only a blank face, or a single dot, representing a one or a zero — would give me the values between 0 and 8 that I wanted. Here, the dice make the decisions: they determine the value. But I didn’t want to roll a dice for every pixel in a 640 by 480 pixel image — that is 307,000 decisions, 307,000 dice rolls.
So I did what people do when decisions are difficult: I asked a computer to make the decisions for me. This program allows me to roll virtual dice and write the pixel step by step. This is efficient: rather than rolling physical dice, I generate a number, dispensing with the need for time spent rolling physical dice. And already, we are learning a lesson about the abstraction of computational models: we need to give up a connection to the real world in both the code we write and the decisions we make.
This program is very simple: it rolls six dice by generating six numbers that are either 0 or 1, then adds them up. I have the option of manually generating each pixel. I can push a button now, and a pixel is produced as if I had rolled the dice.
AI-generated images work the same way: the AI models take images down, pixel by pixel, scouring the breakdown for patterns. In this piece, a bit of code and the images it generates, which I am calling Chance Operations for George Brecht, I reversed the diffusion process. Rather than generating an image from noise, I am generating noise from nothing, one button press at a time.
After pushing the button about 300 times, I had the sense that I had not yet automated my labor. Perhaps we should just automate the button pushing, as well. So I added a button, borrowing the nomenclature from Hugging Faces Dream Studio: “Dream.” Our dream is to be removed from the labor of generating randomness.
This way, I can get back to work while the computer offers a simulation of the on/off dice in the Taming of Chance kit. It rolls the dice and writes the pixel, until the window is complete, and then stops. Now, it doesn’t just roll a set of 8 virtual dice, it also pushes its own button.
If generative AI is about writing pixels based on probabilities, then I am proud to present you with the first generative AI based entirely on improbabilities.
I have no right, of course, to call it generative AI, but why not? It generates an image. It works automatically. It automates my labor. Sure, it has no training data, no patterns become inscribed into the image at all. Instead, it is the result of a computational version of chance, harnessed into a visualization of randomness.
Creating a high definition 4k image in this way requires 8,294,400 dice rolls. This is a complete reversal of generative AI, but it certainly makes art that escapes the reliance and deferral to biased references. Perhaps it yields something closer to Brecht’s vision of unbiased chance being used to create images and art.
At this point, you might be asking: Am I trolling you? Maybe I am. Of course, to our eyes, these images, and all of the images this code might make, are going to produce something similar. There is a constraint here too. It’s not merely the impossibility of randomness in a computerized random number generator - as true today as it was in Brecht’s time. It is also constrained to the bias of an 8-bit system, a way of representing the world according to the simple color capacities of red, green, and blue. We made that decision early on, and its biases continue to become infused in every decision it makes.
we also created a system that focused exclusively on one aspect of the dice roll: the number that it produces. What we erase in this translation is all that Brecht suggested about the complexity of the systems that determine the numbers of dice rolled by hand: invisible and imperceptible influences such as weight, velocity, wind, and so on.
In describing the dice roll to machines based on what we prioritize, we have carved some complexity out of the world. So in a sense, we have trained a generative AI model, because we have given it a human preference that it must rely upon to function. We could use this machine, even this code, to calculate millions of colors and variations, and it would be a simple change of a few lines: add a few more virtual dice, add a broader range.
This code is doing nothing revolutionary. It’s only by comparison to AI that it offers much of anything: a different way of thinking about what the AI image is, and what it gives us. Perhaps we could call it an ungenerative AI. By reducing this concept of choices in an algorithmic image, I hope we can grasp, on a more human scale, how they work, what they do, and reveal both the complexity of the AI generated photograph while surfacing the critical question of: what are we looking at when we look at an AI generated image? Or more importantly, what are we looking for?
Ideas of exponential scale are inscribed into our technologies in ways that make them incomprehensible, and this illegibility is useful to AI companies and those who use algorithms to sort the world. The resemblance to chance, the resemblance to choice and randomness and creativity, are deliberately manufactured. When we share images, we see the content of the image: our photos of people we love, our selfies at the beach. The machines see the order of the pixels. The principle of automated decision making remains the same: the human makes one decision and the system repeats it, over and over again. At scale, these random choices have cascading effects.
They sometimes look like life, because they keep moving between randomness and restriction, local chaos kept within tight bounds. The image we are making here today makes room for the random, makes room for the arbitrary in one sense, that is, the dice are rolled, and the pixel is written, without reference to anything else in the world.
But because it is the product of computation, the randomness of the image is still highly constrained. This image appears to us as chaos, but it is an illusion of chaos, appearing within the constraints of a very rigid system of control. When we make an AI image, we are asking the machine, more or less, to push the pixel making button on our behalf.
But the choices are made through the bias of the human eye, and the bias of how we have labeled images in its training data. Bias serves as a constraint on possibility: in AI, there is no roll of the dice, but rather, a tight restriction to the text and images it has found online, scraped out of noise. But AI takes noise as the start point and strips away real randomness even further, constraints it to the mean. We give these decisions to chance and bias at the same time, but the bias inevitably controls possibility: and what we see in them we mistake for the creative impulse associated with the work of human minds.
So we might ask, in a paranoid register: what is the Amazon feed recommending to us? What was the first decision that started the chain of decisions about who gets a credit card, who goes to college, who goes to jail? Do we think this is life? Or is it merely chance, and randomness, coming together to form something that looks like a natural way of ordering the world?
I am reminded that the origins of computation are in automated decision making, which by default takes choices from the humans who rely on them. The question I pose here is: what are the decisions we want to make, what are the decisions we want machines to make, and why do we respond so emotionally to the assemblage of pixels that image synthesis generates from inferential statistics, aside from its resemblance to the work that we, as humans, can already do?
These machines do not have to reference photography or video. They could be something in and of themselves. Why not ask that these machines make something impossible for us to imagine - and how might we do it?

It is doubtful we ever could, because to make a computer do something, we have to know how to tell it what to do, and we don’t have language to describe what is impossible. For this reason I have no fear of a sentient doomsday machine, or any hope for an AI that someday solves all human problems. To tell a machine how to solve our problems, we’d first have to know how to solve them ourselves.
Beyond this piece, I aim to introduce errors into machines, a way of evoking the unexpected as the machines try to calibrate themselves to my demand that it does something it cannot do. I am curious about how we can glitch them, hack them, in search of some new visual language, some new revelation for how pixels might be rearranged.
Artificial intelligence relies so heavily on human creativity as a source of prediction, recognition, and control. Yet, we risk assigning our decisions to the easiest, limited spectrum of colors and walking away. Instead of asking how we should be using AI, I want us all to ask: How can we stand outside the black box, how can we resist the taming of chance, and how might we let wildflowers grow beyond the fences of our digital gardens?
Thank you.
Eryk Salvaggio
-Sindelfingen Germany, April 21 2024
Things I Am Doing This Week
We have details for my talk at the University of Cambridge on April 25. Link at the button below. It is in-person only at the moment. Here’s the event listing:
A visual artist and a law professor walk into a seminar room to talk about generative AI.
There’s a thought that machines doing busywork for humans are now being enabled to be creative, whereas humans are doing busywork for machines. In this session, Eryk Salvaggio and Andrea Wallace will discuss the realities, tradeoffs, and opportunities, if any, in the automation of creative labour in the visual arts.
Speakers
Dr Andrea Wallace is a Senior Lecturer in Law teaching Art and Law, Internet Law, Legal Foundations, and Torts at Exeter. Her research focuses on intersections of art and cultural heritage law with the digital realm and digital heritage management. She is Deputy Director of the Centre for Science Culture and the Law at Exeter and a co-director of the GLAM-E Lab established in partnership with the Engelberg Center on Innovation Law and Policy at NYU Law School.
Eryk Salvaggio is a researcher and new media artist interested in the social and cultural impacts of artificial intelligence. His work, which is centred in creative misuse and the right to refuse, critiques the mythologies and ideologies of Tech design that ignore the gaps between datasets and the world they claim to represent. A blend of hacker, policy researcher, designer and artist, he has been published in academic journals, spoken at music and film festivals, and consulted on tech policy at the national level.