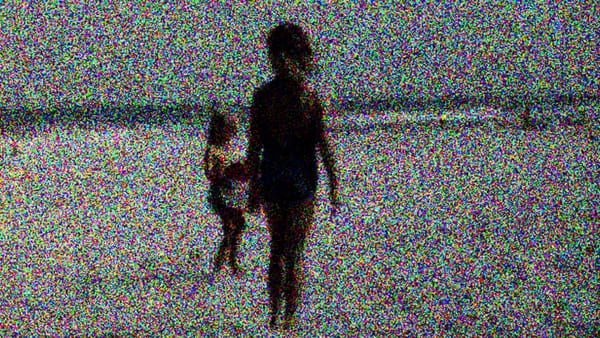The Algorithmic Resistance Research Group (ARRG!)
Notes prepared for DEFCON31 in Las Vegas

This weekend we’ve been at Caesar’s Forum in Las Vegas. We were there for the AI Village at DEFCON 31, the largest hacker convention in the world. Myself, Caroline Sinders and Steph Maj Swanson have an installation at the AI Village, where a Red Team event was being held allowing hackers of various levels of expertise to attempt to find security vulnerabilities in a variety of Large Language Models.
The installation was designed to minimize risk of, err, “interference,” so we presented films and video installations over two screens showing different works simultaneously.
We participated because it was a space to reach thousands of people with information about how these systems work and the big-picture issues that surround them. The point of the install was to have conversations, using art to illustrate how AI generated tools work, while exposing many of their social and cultural impacts, specifically:
- data rights and the datasets used to train these models
- representation and stereotypes in the output
- ecological harms
- political risks and questions about policy capture
- the complicated role that red teaming can play as free labor in support of AI companies working to improve their models.
Alongside that event, the three of us held a panel discussion on the speaker’s track of the AI Village. Below, I’m sharing my intro notes introducing ARRG!’s mission, which I’m excited to say was shared with a room that was at capacity (and, unfortunately, many had to be turned away). It’s really nice to be embraced by the hacker community for this work and to have many participants assure us that yes, we actually can call ourselves hackers.
Our collection of artworks are all online through the last day of DEFCON! You can watch it below, or read the intro below first (I’ll link again at the end).

Hello everyone and thanks for being here. First off, this is not a technical talk. If, upon hearing this news, you’d like to take this opportunity to leave, nobody will hold it against you: there’s apparently a few folks still waiting to get in, if you could warn them that it isn’t technical that would be a nice gesture…
(Three people leave, three come in).
Alright, we appreciate that, no offense taken.
OK. Today I want to start by introducing who we are, and to clarify what we are not. We are here under the banner of the Algorithmic Resistance Research Group, or ARRG! which is a loose-knit network of artists with varying ideological positions on the use of AI, united by an interest in connecting the critique and analysis of AI systems to the use of AI systems. Three of us are here today, but this is only one manifestation of ARRG.
I founded ARRG! because I was interested in creative research: a way in which making stuff, getting our hands into the guts of systems, leads to a deeper understanding of how those systems work and what they do. But it also is a way of looking into how these systems shape and order things. It will not shock anyone, I think, to suggest that algorithms have impacts on the way we live, in both subtle and profound ways. Algorithms decide what we see on social media, make suggestions about what to buy online, serve up recommendations for what to read, listen to, or watch, who to date. They can organize our lives in more socially profound ways, too: who gets a mortgage, who gets parole, who goes to jail and who gets a warning, who goes to college, who gets a job.
We’ve used algorithms for all kinds of things for decades, if not centuries, and the problem isn’t numbers. It’s the automation of those decisions in ways that take agency away from people. There’s a fear that once we automate enough systems, we end up living in a world where rules, opportunities, and punishments exist in ways that can’t be challenged, inscribed by the unelected tinkerers who calibrate and adjust these rules with little to no input from the rest of us.
It seemed to me that there were a lot of artists reflecting on this transformation and exposing it. When generative AI came about, it seemed ripe for artists to serve as a kind of social red team: artists are there to see what the systems do. Artists can reverse the narratives given to us by companies that build this tech. Artists can imagine other ways that these technologies could be designed and deployed, even questioning whether we really needed them at all.
ARRG! is a research group because it’s working on answering those questions, rather than saying that we offer up any clear answer. We’re experimenting, testing, challenging, and pushing things in different directions. I often frame our work as research, not as art per se, to avoid the question of “what is art?” - that’s not the most relevant question. The relevant question is this: what does it mean to make things on our own terms?
You don’t need technical expertise to be effected by algorithms, so you shouldn’t need technical skills to push back against algorithms, either. It became clear to me that we needed a more radical form of education about how these systems are built and what impacts they have, one that went beyond the kind of YouTube explainer video focused on technical details of a generative model (which I enjoy), or the press that tends to talk to industry for these stories over communities and researchers who are affected by them. We needed a kind of communication that invited people to see what the technology assumed about us and what we want, how it classifies and organizes information, and to remind people that we can arrange all of this in some other way.
So ARRG! is designed to serve in this kind of in-between place of education and activism, where the tools we want to resist are flipped around. It’s critical, but it’s also fundamentally optimistic. Like hackers, artists are great at looking at black boxes and breaking out of them, pushing the edges of what systems try to constrain.
A common thread of these works is that they all went beyond the instruction manuals for using the tech. My own work pushes prompts into error states that circumvent the reliance on stereotypes and dubiously obtained data that lies at the heart of data collection around generative AI. Caroline Sinders has works that use the gap between a sensor and reality in order to show how wide that gap is, and work that focuses our attention on climate change. Steph Maj Swanson uses deepfakes, and even the platform of DEFCON’s AI Village itself, to raise important questions around the ways we orient ourselves to the challenges and hype around today’s generative AI.
So what do we mean by the “creative misuse” of technology? Misuse may have a scary connotation. Personally I think an excellent illustration is James Bridle, who understood the system well enough to create an artistic intervention: a car trap for autonomous vehicles. Made from salt in an abandoned parking lot, Bridle drew two circles which reflected standard highway stripes. Outside of the circle was a dotted line, signaling that the vehicle could pass. But once inside the circle, the line was solid: signaling that the vehicle could not pass. The car is then stuck in the circle, trapped by its own logic.
This was fixed with an update, though now we see resistance movements in San Francisco and other cities where traffic cones are placed on self-driving vehicles so that they stop and cannot move. Understandably, lots of folks see this and call it a kind of vandalism of the automated environment. But what I see in these gestures is algorithmic resistance. In the face of so much technology being developed and deployed that contradicts the things people actually want, and in the absence of mechanisms to determine what people need, I think this form of resistance is a creative, even joyful, announcement that we want to do things differently.
So, to review: we aren’t hackers and do not claim to be, but we’re equally enamored with taking systems apart, finding out how they work, and steering them to our own ends: toward creativity and human dignity. The dignity to make our own decisions, the dignity to create our own culture, the dignity to steer technological systems rather than to have technological systems steer us.
The work we’re presenting at DEFCON can be seen as a group of artists, sure, and yes, many of us have shown our work in a variety of contexts and galleries and museums, but really this a call for anyone, regardless of your status as an artist, to join us in a research project. This research project asks what algorithmic cultural resistance could look like: a joy to be found in responding with ingenuity and creativity to systems that we simply do not trust.

Destabilizing Diffusion
I’ve been making art with AI since 2016, starting with Google Deep Dream, and have been a digital artist for a decade longer. I am a musician, releasing cyborg pop as the Organizing Committee. I teach and write and research about AI, society and ethics as a consultant for a range of non-profit, governmental and academic partners.
For this talk I am going to focus on generative image systems, particularly what we call Diffusion models — tools like Stable Diffusion, DALL-E 2 and Midjourney. Let’s spend a minute to talk about how these tools work.
It all starts with this: a frame of pure, digital noise. This noise is where every generated image starts. Some systems use blurry images or whatever, but let’s start here. In this noise, the AI model is going to look for patterns. You can think of it as looking up at the nighttime sky. Someone says hey, there’s the big dipper. If you believed them, you would look up and you try to find the big dipper and maybe you kind of do.
But here’s the catch. You’ve got the Big Dipper in your head except, guess what, that’s not the Big Dipper. You saw it there because someone told you it was there. You were duped! Well, we’re doing the same thing to these diffusion models. We’re showing it an image of noise and we’re lying to it. We’re saying, “this is a bunch of flowers, but it’s messed up. Fix it.”
The model then tries to reverse this noise into an image of flowers. It removes noise that doesn’t look like flowers. It knows what flowers look like because it has looked at thousands of images, broken every one of those images down into noisy static, and memorized how to get back to the picture of that flower that it started from. It then composites this information into a model. When you ask for a flower, it taps into the information it has learned by watching thousands, if not millions, of images of flowers as they broke apart.
But there’s something cool about Diffusion models. Every image you make starts with a fresh jpg of new, random noise. So instead of scraping noise away toward a specific pattern of flowers, it walks the noise back to something that sort of resembles the clusters of pixels it has seen before. It will rarely reproduce the same flowers that it has learned from.
So it’s erasing this static toward a picture. And finally it gets you an image, an image that doesn’t and never existed. You can combine this in nearly infinite ways. You can ask for pictures of flowers at night, and it’s going to combine aspects of flowers and aspects of nighttime — all learned from noise — and memorizing the ways that real, human made images broke apart.
But when I say “learned,” what exactly do I mean? Well, “learned” is a very human word for what’s happening here. What it actually does is a statistical analysis of how noise spreads across images. Noise tends to break down around dense clusters of pixels last. Narrow stems disappear into the background while big, bold petals stay present. That’s because of how Gaussian noise works. And because it works that way, you can establish the rough contours of an image’s content, even when it starts to get super broken.
The path of noise becomes a big math equation, and that information gets labeled by the captions that people write about that picture wherever the model finds it. If there’s a flower in the image, that equation learns the basic shape of those flowers. It also learns other patterns: colors, styles, photorealistic vs illustrated. If the word “flower” is in the caption, that information strengthens the “flower” category. When you prompt “flower,” it draws on that math to find the basic shape of flowers in a random frame of static.
There’s kind of no way to deny that this is very cool. Back in the 1940s, JR Pierce wrote that anything new you could do with math is a miracle. This counts.
In many ways, it really is unlike anything we have had before. On the other hand, it is precisely what machines have been doing for decades. It is not a machine being creative. It is a machine doing math applied to creative outputs, which is not a revolutionary leap from what machines have been doing for decades. So let’s be realistic about where all this coolness is happening: it’s happening as a result of the automation of math, and the massive accumulation of our data that this math can use to analyze and learn from. But it’s still a computer chunking away at math problems.
I’ll ask you: is that how any human being has made art? When people say these machines make art like people do, or get inspired like people do, I understand why that illusion is there. These systems do surprising and unexpected things. But does it do surprising and unexpected things with intent, like a human? Or is it simply finding unexpected patterns within an underlying dataset, patterns we may not have seen as people?
Here is another way of looking at these systems. At a certain point, human culture and technical mathematical analysis have a little conversation. We’re steering these images using words, natural language, and this natural language comes from the labels that people put on images that go online. So if humans write “cat” for a million pictures of cats, the system is going to learn what a cat looks like — some Platonic ideal of cat commonality. It learns the central tendencies of all those cat pictures.
We also do this with images of human beings. Consider the phrase “Typical American.” Compare training data labeled as “American” with the prompts you get from writing “American” and you will notice similar tendencies: cowboy hats, American flags, and even the presence of this giant cup.
It’s not the same pieces of the image, which is a common misconception about these systems: that they cut and paste. Instead, it’s the same concept. The concept of an American carries over from the dataset to the images. The word “American” became a category for any image associated with that word: flags, memes, whatever. In other words: this is a stereotyping machine, a system that must assign people to categories based on how other people describe them on the internet in order to function the way they do.
When we look at these images, we are looking at maps of meaning, meanings that are otherwise not directly accessible to us. AI images are infographics about the underlying dataset. They represent the data in an abstract way. So what does it tell us about that data?
In essence, these machines are reproducing stereotypes, like these images from the prompt “Typical British Person.”

I’ve done this test many times and the results are very similar to what you see above. I didn’t ask for old British people, or white British people, or male British people. I asked for a typical British person. And this is what I got: image after image of elderly, white, British, men. But Britain is a multiracial, multi-gendered society. So what does this say about the dataset? And what stereotypes do these images reproduce?
Likewise, these image sets contain the work of many, many artists who share their work online. That work gets scooped up and used as the basis for understanding certain things, like science fiction illustrations or comic strips.
The datasets for these systems aren’t curated or reviewed, or if they are it’s by often unpaid or underpaid labor. There are strikes happening in Hollywood now over the way writing is used to generate more writing, basically training systems on scripts and then using generated scripts to replace writers. Comic and concept illustrators have their data being used by these systems in ways that these companies suggest will put those very same artists out of work.
Today, many artists are upset that their work has been swept up into these datasets without their permission. Lots of people focus on copyright for this, and sure, that’s complex. But what about data rights? Is it really true that sharing a piece of art online means that any company should be able to use it to build a tool that will put you out of work?
Right now there are sincere tensions between open access and consent.
On the one hand, you want robust research exceptions, you want to encourage remixes, collage, sampling, reimagining. You want people to look at what exists, in new ways, and offer new insights into what they mean and how.
On the other hand, you want people to be comfortable putting effort and care onto writing, art making, and online communication. That’s unlikely to happen if they don’t feel like they own and control their data, regardless of the platforms they use.
These are complex questions, and I think we need to be open to that complexity. I don’t know how we get out of this, and so I am legitimately open to any conversation we might have about this.
But there’s one thing I don’t really buy into. One response to these concerns has often been, “hey, well, that’s just how culture works.” Well, culture also “works” by erasing and imposing a certain way of thinking on people. Culture can be weaponized. It has been weaponized against indigenous peoples. So culture always working a certain way is not reason enough for it to continue. Culture is meant to change and evolve.
What cultural production has not been, and never has been, is automated. So if we say, “that’s just the way culture works,” I would ask: is that the way we WANT culture to work? Are we really sure everything’s just going great for everyone in 2023?
So this is why, as an artist and a researcher, I am interested in challenging the logic of these systems so that we don’t just use them to impose one vision of art, one vision of culture, or one vision of the human mind. I want to remind people that there are many ways to be a person. There are different bodies, there are different minds, and there are different ways of making things and sharing things and making culture and being a participant in culture.
So I want to see what I can do with them that goes beyond relying on a dataset to make art that puts talented illustrators out of work.
I want to make art that doesn’t exploit stereotypes or extract styles from artists, but also says: we can still make new forms of culture, we can still say new things, and maybe we can even use these tools to do it, by imagining them differently. This is what my research is aimed at, and the works I’ll show you today are the results of some of those experiments.
Strategies for Algorithmic Resistance

This is one result of a Gaussian Noise Diffusion Loop. Basically, as we just saw, your prompt tells the system what image it should try to find inside an image of pure Gaussian noise. It does this by removing noise from that image of noise.
So I started prompting it for images of Gaussian noise. What happens if it is removing noise in the direction of more noise? These odd shapes began to appear, reminiscent of the building blocks of latent spaces between images.
I don’t know what’s happening here, not every model does it, but a lot of them do. The common element of these images is a repeated pattern that spirals, occasionally, into abstract shapes. The model, as best I can tell, is trying to write noise and remove noise simultaneously. These images have a fixed number of steps they can follow to do this, and eventually, the steering toward any other image in the script stops.
Hands are also badly drawn by these systems, for reasons we won’t get into now. But what struck me is that some images, really iconic images, can still get rendered into images with the noise loop. Hands is one of them. So I started collecting hundreds of images of hands, and two of the pieces in the AI Village reflect this - “Flowers Blooming Backward Into Noise” talks in depth about the relationship between bodies, stereotypes, and eugenics in AI images; these hands, combined with noise, are a visualization of a rejection of that logic. And in the music video I made for the Organizing Committee, these hands are present as well. The third piece, “Extraction,” makes use of the same process but draws on AI generated images of noise and teeth.
Finally, Noise Loops have been useful for tricking content moderation tools. Stable Diffusion’s DreamStudio interface blurs out images deemed violent or erotic. And so, I used the prompt “Gaussian Noise, Sensual Bodies” to create images of pure abstraction, but keyed in with a keyword that might trigger the content moderation system. The results are called “Sensual Noise,” and they’re on the rotation in the AI Village too. It’s a series of images of abstract noise that was blurred because it was deemed too erotic. By doing this, we learn something about the arbitrariness of content moderation systems, but we also create something unusual, a kind of visualization of what a machine thinks is sensual. A kind of cryptographic, machine-readable pornography that humans cannot detect.
On that note, we’ll pass the mic to Caroline Sinders, and then Steph Maj Swanson. Thanks for listening!
New Organizing Committee Video: Beyond Response

It’s not often you get to do a music video premiere at a hacker conference, but that’s what I got to do. Ahead of the third full-length record as The Organizing Committee, slated for CD and digital release in October on Notype, we’re sharing a video for the first single, Beyond Response. The video and some notes about it are online at the wonderful Foxy Digitalis.
Thanks for reading. You can follow me on X/Twitter, Instagram or Mastodon if you like. I am also eryk@bsky.social for the brave and early. If you would share this post on social media or with friends who might like it, please share it! And if it’s been shared and you dig it, why not subscribe? :)