Writing Noise into Noise
Diffusion models can't draw hands. They also can't draw static.

Diffusion models all start in the same place: a single frame of random, spontaneously generated Gaussian noise. The model creates images by trying to work backward from the noise to arrive at an image described by the prompt. So what happens if your prompt is just “Gaussian noise?”
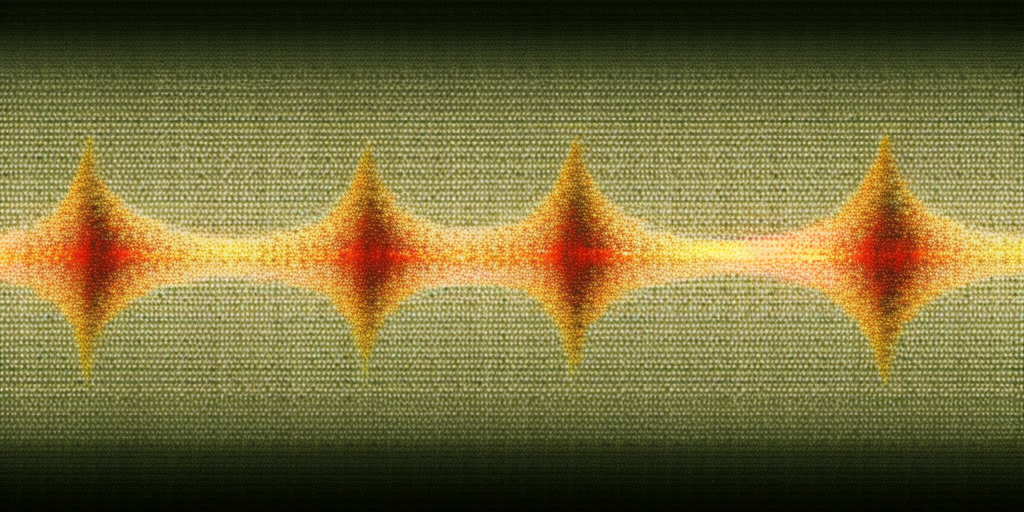
The answer is the image above. One would think that requesting Gaussian noise would create an image of static - that’s what Gaussian noise is. You might also suspect, after a quick Google search or scan of LAION data, that the model might give us images of charts, which dominate the first pages of both datasets. You might wonder if there was some art movement associated with Gaussian noise, but no.
I was intrigued. If the above image wasn’t Gaussian noise, and it didn’t represent anything associated with “Gaussian noise” in the training data, what was it? Keeping with my methodology for “reading” AI images, I produced a few more.



Now I was able to look at them closely and see if I could find patterns. I did: the weaving pattern, looking like extreme close up of old sweaters. Bands and stripes. Occasional bursts. Even in the top image, a strange symmetry, a pattern.
“Gaussian Noise.” I wanted to try this prompt because all images start with Gaussian noise to begin with. I imagined it like imprinting an image of a flower onto an image of a flower. In the physics of photography, you’d have a strange double-exposure effect.
But Diffusion isn’t photography. We have to think about what the model is doing, which is creating a variation on that image of Gaussian noise, with noise removed. The noise is removed in the direction set by the prompt.
In theory, the machine would simultaneously aim to reduce and introduce noise to the image. This is like a synthetic paper jam: remove noise in order to generate “patterns” of noise; refine that noise; then remove noise to generate “patterns” of noise; etc. Recursion.
In simple terms: The model would have a picture of Gaussian noise in front of it. And it would look at it and say: “OK, I have to remove this Gaussian noise until I get to Gaussian noise.” It has, say, 70 attempts to make a variation toward that image (you tell it how many steps). At every step it removes some noise, and compares that image to the last image, and tries to find patterns in the new image that resemble… Gaussian noise.
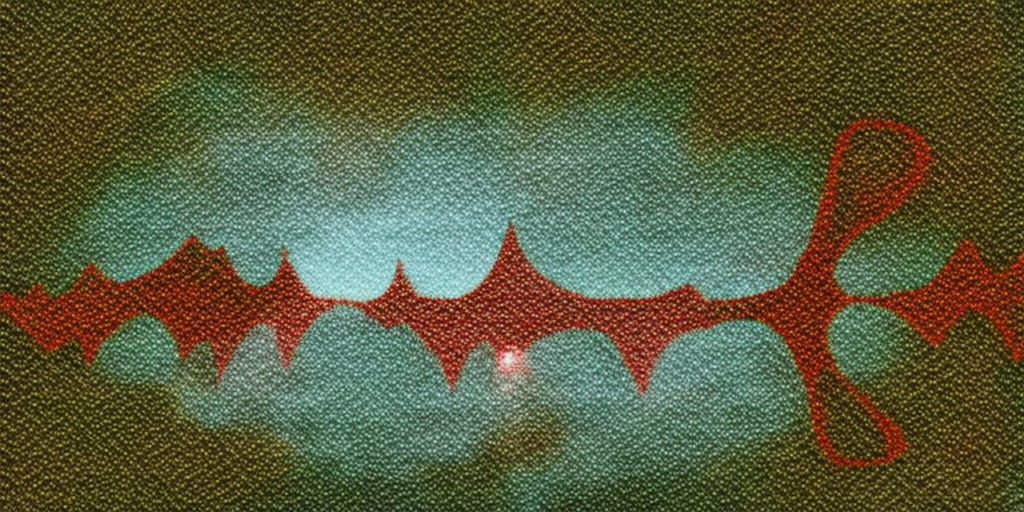
I have a theory that this is not a representation of anything the model has learned. I think… or hope… it’s a glitch: the process of the recursive writing and erasure of noise. Every removal of noise from that starting image would lead to a new image where some lines were sharper. The model would look at that image and introduce Gaussian noise, then erase that noise back in the direction of whatever it has internalized as “Gaussian noise.”
It’s tempting to link this weaving pattern to actual textile making: that noise weaves in, then out, of some lattice. I suspect that this metaphor is pretty close to the truth. If you take an image of Gaussian noise into Photoshop and denoise it enough, you end up with pixelated squares and lines. In Diffusion, any square, any line, is the source of some new pattern to be extrapolated outward. Slight variations in patterns would be amplified. What we’re seeing could be the logic of Diffusion models stuck in this feedback loop.
I am skeptical of this theory, because it’s nearly impossible to tell if the model is producing a representation of Gaussian noise or is giving me images that emerge from an error state or recursive spiral. But I don’t know what the hell this is supposed to “represent.”


Finally, I wanted to test if the presence of Gaussian noise in a prompt created any kind of additional effects. In the case of some complex prompts, it cancelled the prompt outright. At the top, you see an image generated by “human body.” On the bottom, the result of the prompt “Gaussian noise, human body.”

If these images were representational, you would expect some semblance of presence of human bodies in the lower images. But it seems that the need to write “Gaussian noise” into the image has sidetracked the model from ever getting to a place where human bodies could start showing up.
This would suggest that the lattice-ey images are errors. However, simpler prompts are still represented in the images, such as these, from the prompt “Gaussian noise, human hands,” combining what seems to be two of Diffusion’s least favorite things.
I have to say, I quite like them, even if they complicate the question.



It’s hard to say what the hands mean about how they are being rendered — to be clear, Diffusion is always bad at drawing hands. These images seem like some mix of representation, with some elements of the alleged “error states” present. Is it possible that errors and representations could co-exist? Possibly. But it has made me extra cautious about what to believe.
The images have a third explanation, which is that Gaussian noise is a matter of individual pixels, and Diffusion is unable to abstract these kinds of details - notoriously getting lost in the contours of skin wrinkles and fingers, as seen above. Gaussian noise may be another example of extreme detail driving the system into over-rendering based on nearby clusters. In fact, that’s exactly what it looks like.
If so, then yes: it is an error state, rather than a representational image. And while error states in representational images (hands being weird) suggest one thing, entire frames resulting from these errors seems like something else. I
It’s more interesting to me, anyway, because it would suggest some exciting new aesthetic limit for the system. I am still intrigued by these outputs: it doesn’t make sense to me that noise would be represented in this way, which looks a bit like classic oscillons blended with weaving.
Error states are a way to see into the actual aesthetics of machines. In the Situationist sense, the only truly generative things machines produce are mistakes. When they operate according to a set of commands, they’re simply tools. When they introduce distortions and failures, we see their limits as mechanisms for something else. Something unintended. And it is the limits of technology that fascinate me. The vulnerabilities.
When I lived in Japan, I used to love karaoke, because it was where you went to listen to your friends’ voices crack. People could sing well, but that was beside the point. The most interesting art for me has never been about hitting every note. It’s the ways in which we can so distinctly miss them.
At the very least, we have learned that AI can’t draw Gaussian noise.
This Week in Class:
Generative Adversarial Network Fever
We looked at Generative Adversarial Networks (GANs) and how they might reinforce — or disrupt — the logic of archives. How do the images generated by these systems tell stories about the underlying datasets? How can we, as artists, use this process to tell our own stories? We will also look at the history of GANs and their early reliance on datasets of European oil painting. How do the archives available to us shape the work we make? How do these datasets reflect cultural contexts of museums and digitization?
We’ll look to the work of Hannah Hoch, Lorna Simpson, Helena Sarin, Mario Klingemann, Gene Kogan, Obvious, and Robbie Barrat.
Tune in to The Data Fix!
I was delighted to be a guest on Dr. Mel Hogan’s podcast, The Data Fix, to talk about AI images and how they’re made. The episode was released this week, and you can find it on the link below.
Thanks for reading! If you like what you’ve read, you can subscribe — or share it with a friend or your social media contacts. It’s always great to get new readers, and that’s the only way that happens. You can always find me on Twitter, Mastodon or Instagram. Thanks!